
Python is used in a wide range of fields around the world, including website development, artificial intelligence, task automation, data analysis, data visualization and much more. In order for all of this to be possible, data plays quite a crucial role, which implies that it must be stored efficiently and we should be able to access it timely. So, how do we go about accomplishing this? We use something called data structures.
Data structure is one of the most fundamental concepts of computer science and an indispensable tool for any programmer. Whether it's a real-world problem or a simple coding query, a comprehension of data structures is important for finding the correct answer.
In this article we are going to have a detailed discussion about the different types of data structures in Python, and understand them while getting our hands dirty with codes. Let’s get started!
Diving into Data Structures
As the name suggests, data structures are basically structures that can hold some data together. In other words, this is a way to organize and store information, relate them and perform logical operations accordingly.
Classification
Data structures can be categorized in a variety of ways. One method is to classify them as primitive or non-primitive data types. Primitive data structures are the most basic forms of representing data, hence the name primitive, whereas non-primitive structures are meant to organize and handle sets of primitive data. Rather than storing a single value, non-primitive data structures store a collection of values in various formats.
Non-primitive data types include List, Array, Tuples, Dictionary, Sets, and Files, while primitive data types include Integers, Float, Strings, and Boolean. In Python, there is another type of data structure called user-defined which is basically derived from an existing data type. Stack, Queue, Linked List, Tree, Graph, and HashMap are examples of these.
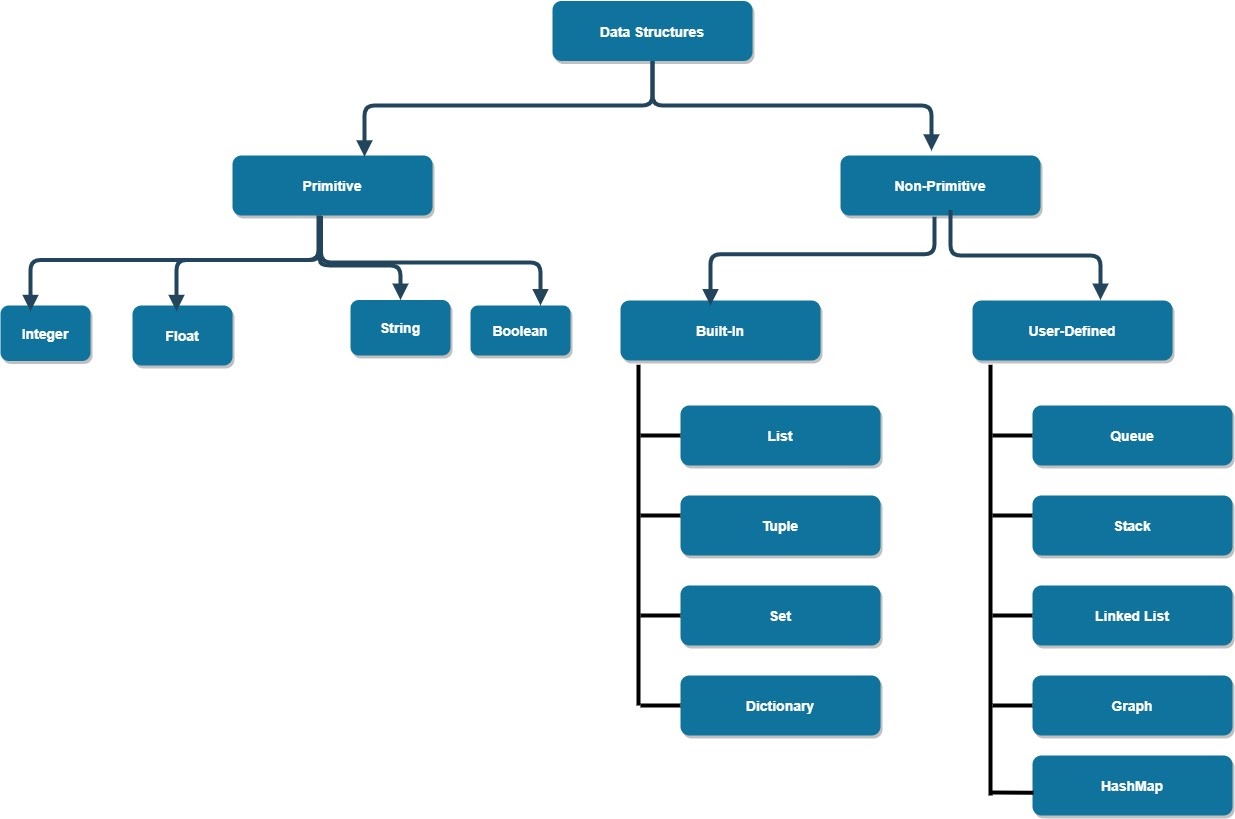
Primitive data structures:
These are Python's basic data structures that contain just simple and pure data values, and are used to manipulate the data. Let’s check out the four types of primitive data types in Python:
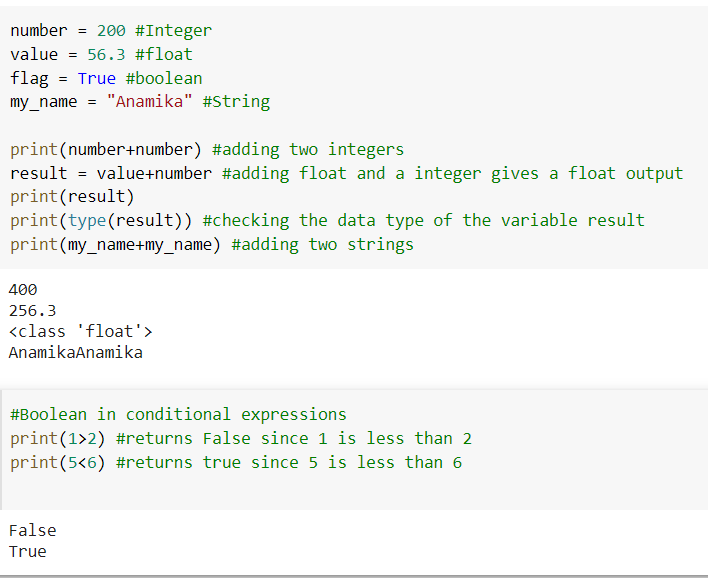
Integers
This data type is used to represent numerical data without a decimal point, such as positive or negative whole integers. For example, -1, 2, 7
Float
This data type is used to express rational numbers with a decimal point, such as 8.0 and 7.77. Because Python is a dynamically typed programming language, we do not need to declare variables or their types before using them. Every variable in Python is an object.
String
A collection of alphabets, words, or alphanumeric characters is represented by the string data type. It's made up of a string of characters enclosed by a pair of double or single quotations. For instance, 'house’, “home” and so on.
Boolean
This data type can take the values TRUE or FALSE and is useful in comparison and conditional expressions.
Built in data structures (non-primitive)
These Data Structures are pre-installed with Python, making programming easier and allowing programmers to get solutions faster. Let's take a closer look at each of them.
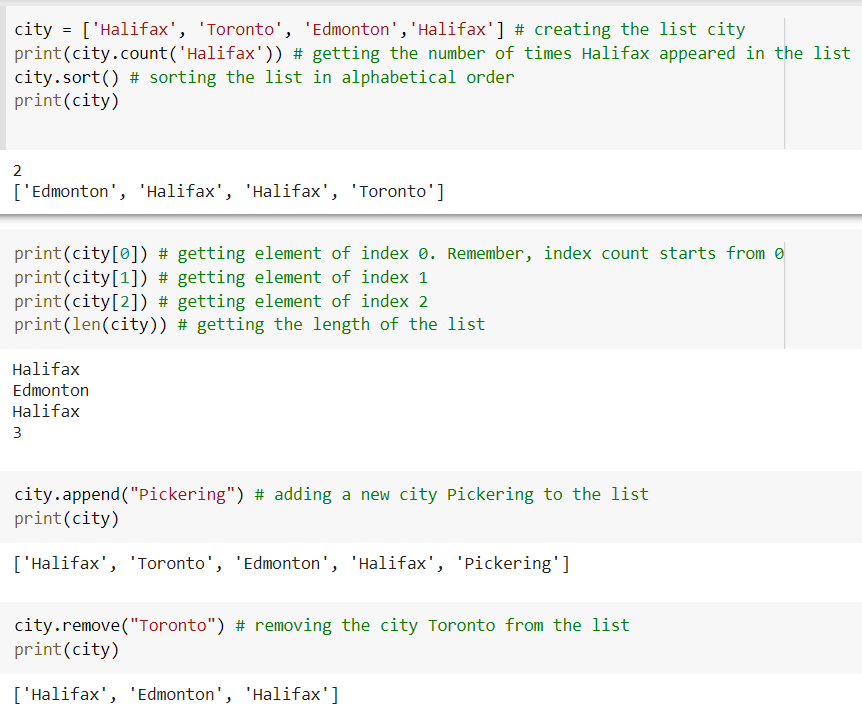
List:
A list is a data structure that can be used to represent a sequence of items indexed by their numeric position. Lists can have zero or more elements, and they can be of any type (including objects!). Lists are useful because they enable the creation of deep and complicated data structures. Every element of the list has an address, which is referred to as the Index. The index value starts at 0 and continues until the last element, which is referred to as the positive index. Negative indexing, which begins at -1, allows us to access elements from the last to the first.
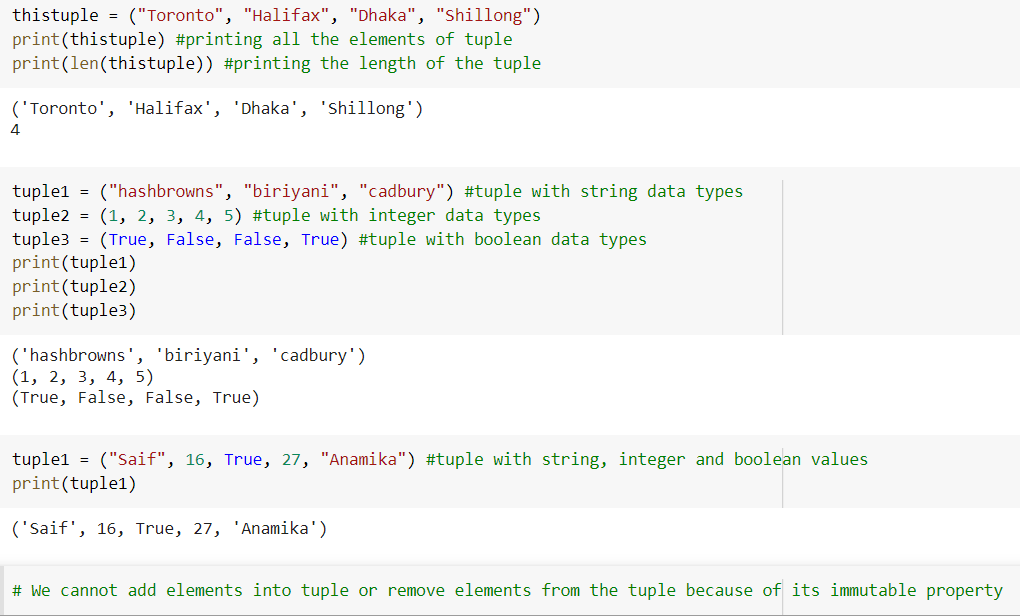
Tuple:
Tuples are similar to lists, with the exception that once data is placed into a tuple, it cannot be modified. Unlike lists, tuples are declared in parenthesis rather than square brackets.
Tuples are typically used when a user-defined function can reasonably presume that the collection of values will not change.
Set:
A set is a Python data structure that contains things that are not sorted or indexed. The following are the characteristics of a set:
- There are no duplicate items in a set. No matter how many times we add an item, it would appear only once.
- The elements of a set are immutable, i.e, that they cannot be changed, but the set itself is mutable since we can add or remove elements from the set.
- Sets don't support any slicing or indexing operations because their items aren't indexed.

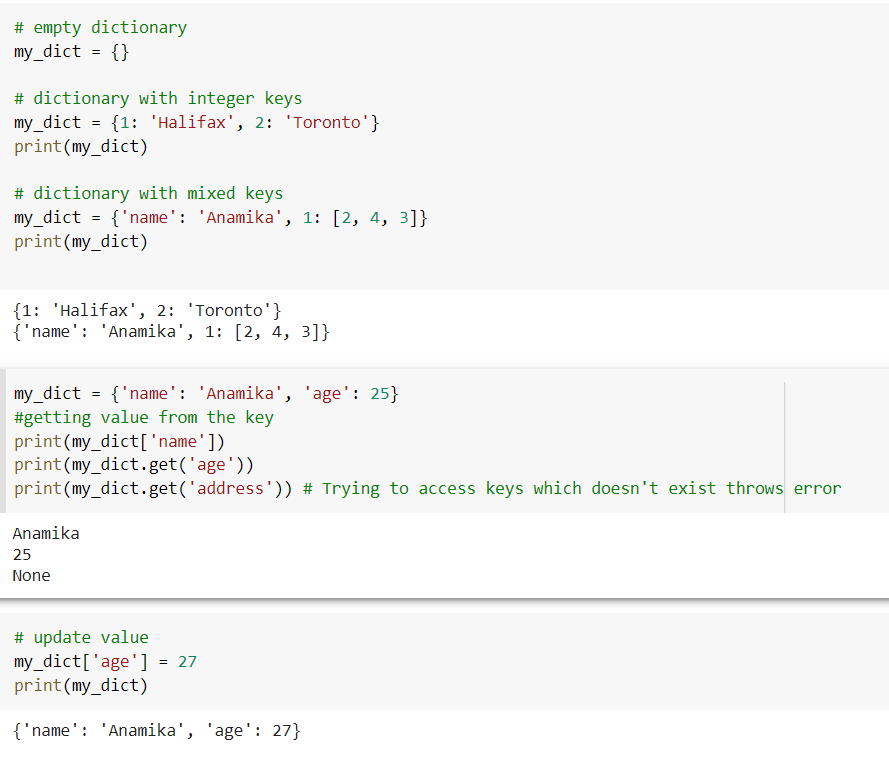
Dictionary:
A dictionary is similar to an address book in which we may find a person's address or contact information by knowing only his or her name, i.e. we associate keys (names) with values (information). It's worth noting that the key must be unique, just as we would not be able to find the relevant information if we have two people with the same name. Key-value pairs make up dictionaries. The 'key' is used to identify an item, while the 'value' is used to store the item's value. The key and its value are separated by a colon. The items are separated by commas, and everything is encased in curly brackets.
User Defined Data structures (non-primitive):
User-defined data structures are data structures that are not supported by Python directly but can be designed to perform the same functions using concepts that are supported by Python.
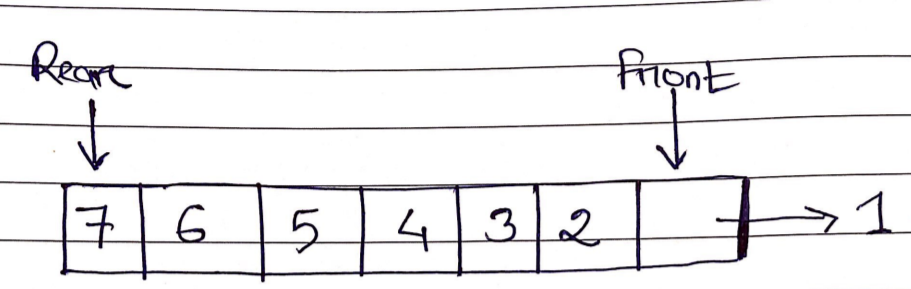
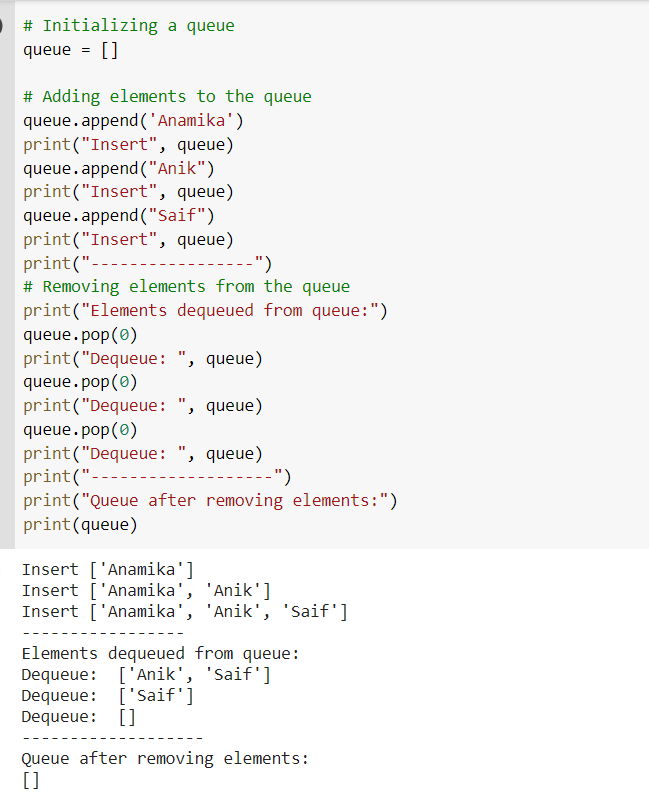
Queue
A queue is a linear data structure that holds objects in a First-In/First-Out (FIFO) order. The data element that was inserted first in the queue will be removed first.
Some of the important methods of queue are:
- put(item): This inserts an item into the queue.
Time complexity: 0(1)
- queue.get(): removes and returns a single item from the queue.
Time complexity: 0(1)
- queue.empty(): If the queue is empty, it will return true; otherwise, it will return false.
Time complexity: 0(1)
- queue.qsize(): returns the size of the queue.
Time complexity: 0(1)
- queue.full(): If the queue is full, full() returns true; otherwise, false.
Time complexity: 0(1)
Stack
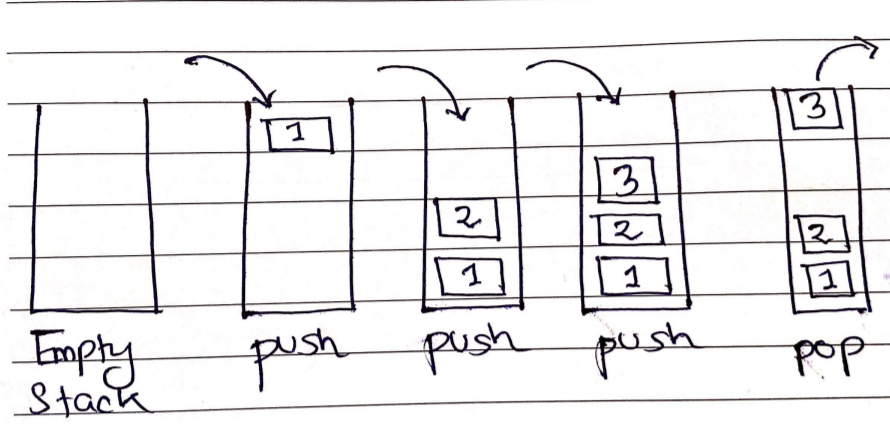
A Stack is a linear data structure that uses the Last In, First Out (LIFO) mechanism to store items. A new element is always placed at the top of a stack, and the top element always gets removed first. Some of the stack methods are:
- stack.isEmpty(): If the stack is empty, the isEmpty() method returns True. Otherwise, False is returned.
Time Complexity: O(1)
- stack.length : The length of the stack is returned by the stack.length() method.
Time Complexity: O(1)
- stack.top () : The stack.top() method returns a pointer or reference to the stack's top member.
Time Complexity: 0(1)
- stack.push(): The element x is pushed to the top of the stack using the stack.push() method.
Time Complexity: 0(1)
- stack.pop(): The stack.pop() method returns the stack's top member after removing it.
Complexity of Time : O (1)

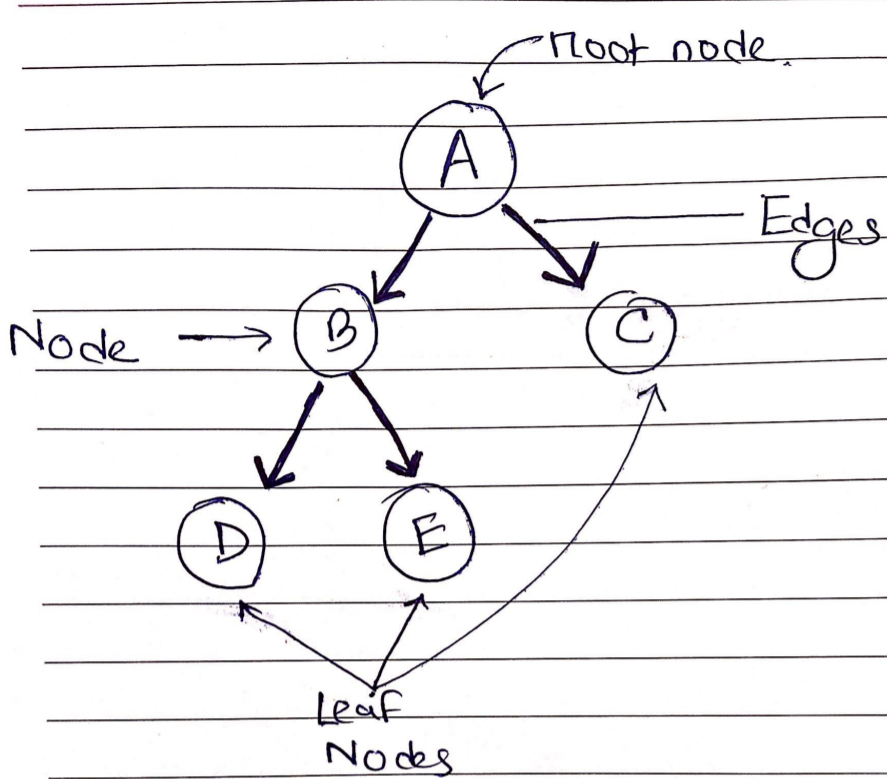
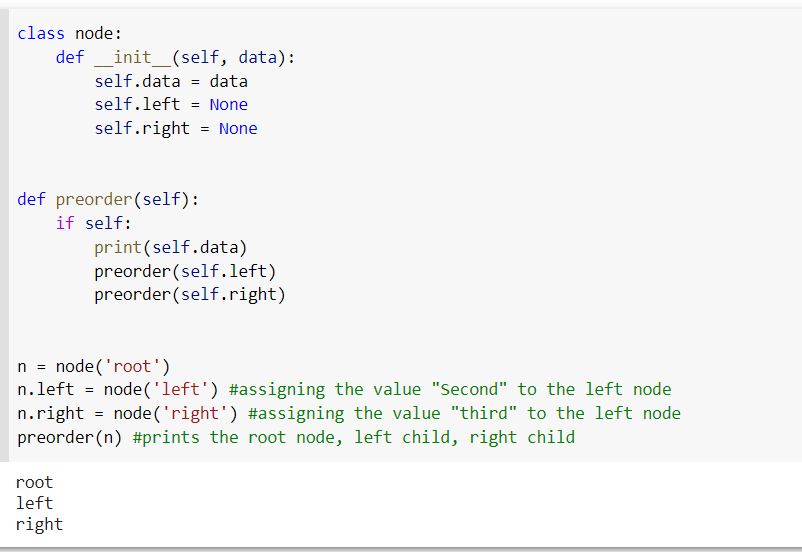
Tree
Trees are non-linear data structures in which nodes are linked by edges. The root node serves as the Parent node, while the left and right nodes serve as Child nodes.
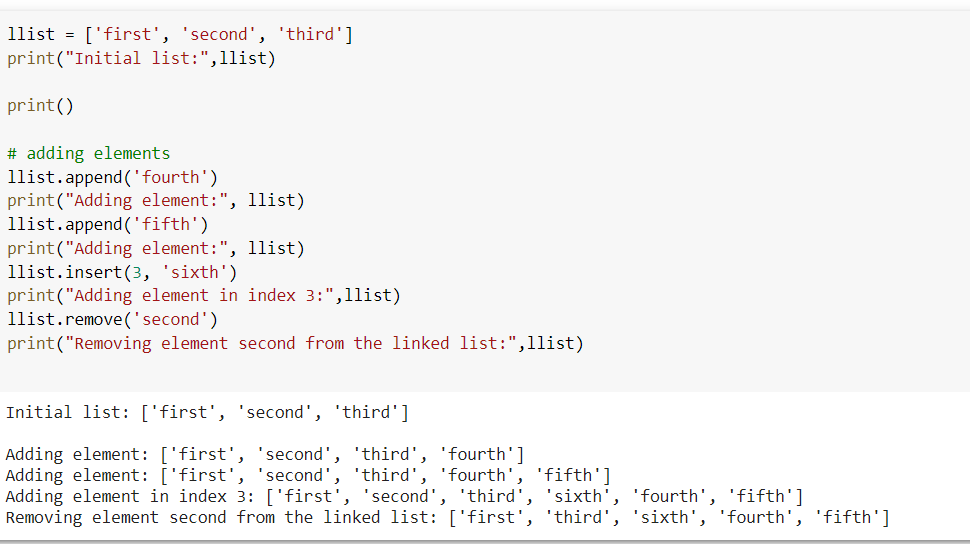
LinkedList
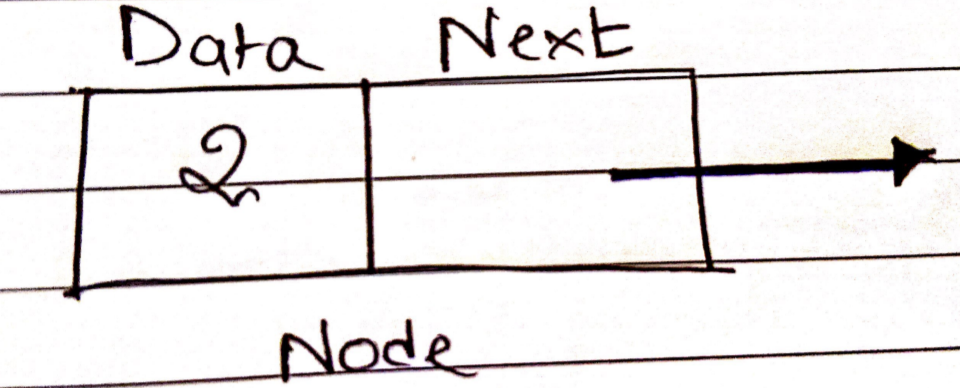
A linked list is basically a collection of nodes. A node is made up of two distinct fields:
The value to be stored in the node is contained in “Data”.
The next node on the list is referenced by “Next”.
Here is what a Node looks like:
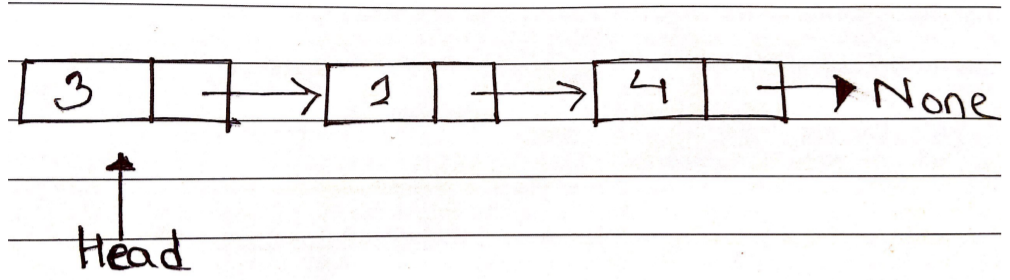
The head is the first node in a linked list, and it serves as the beginning point for any iteration of the list. To establish the end of the list, the last node's next reference must lead to None. Here is how a linked list is structured:
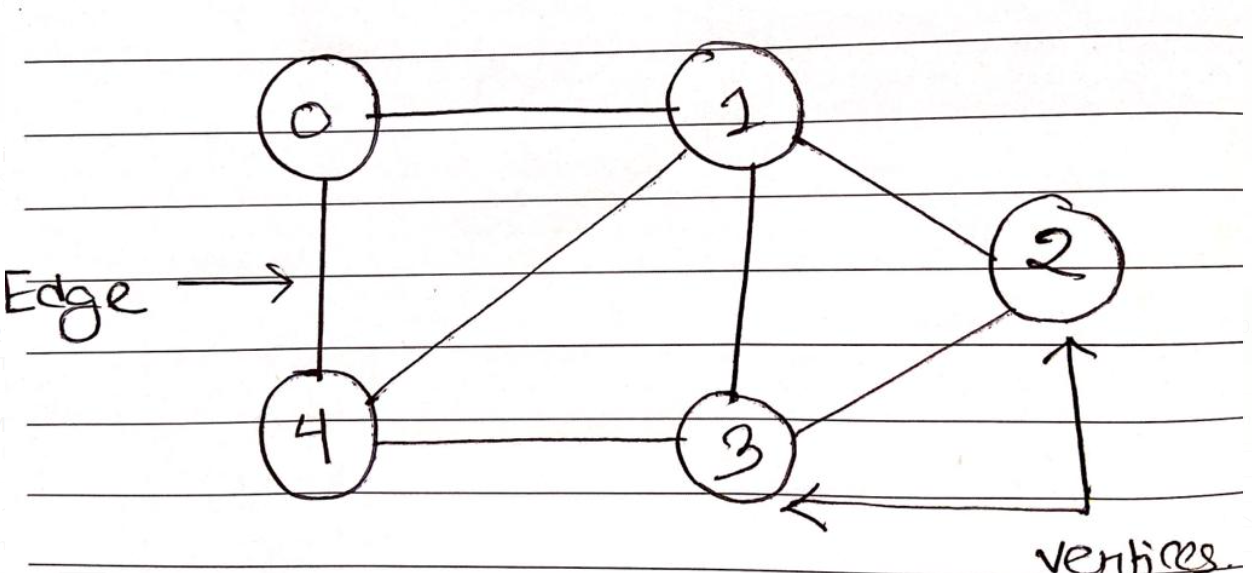
Graph
A graph is a non-linear data structure made up of nodes and edges. The edges are lines that connect any two nodes in the graph, and the nodes are also known as vertices.
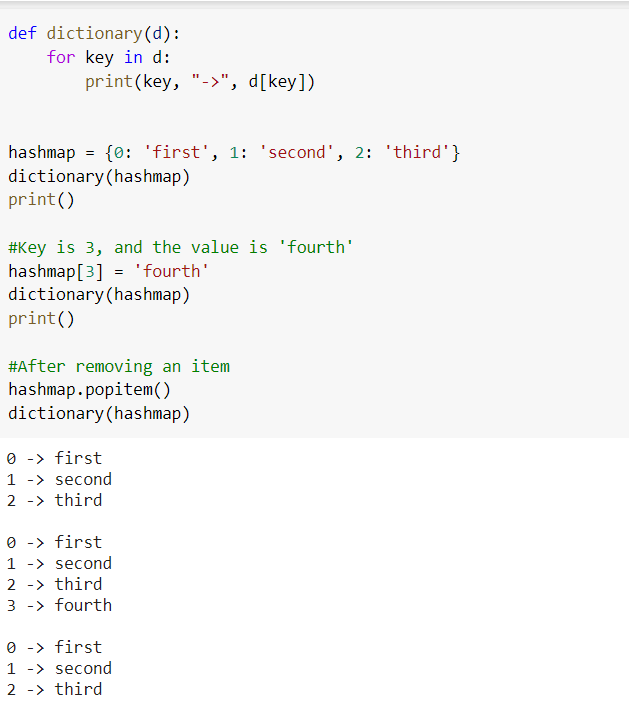
HashMap
Data is stored in hashmaps as key-value pairs. A hash map uses a hash function to compute an index into an array of buckets or slots using a key. Its value is assigned to the bucket with the appropriate index.
The key of hashmap is unique. When the same key is inserted again, the most recent insertion is remembered, or the key's value is replaced with the more recent edition. Hashmaps don't have any synchronisation. It means that any (key, value) pair additions or deletions are done at random. Furthermore, hashmaps can only have one null key. Multiple null values, on the other hand, are possible.
For more information, please check What are algorithms?
.png)





